Actor model in Go

What is Actor model#
Imagine that you’re queuing at a fast food drive-thru to buy your morning breakfast. Each meal has multiple lanes to get your order. The waiters are working very efficiently, and it only takes microseconds or nanoseconds to take your order and pass it to the kitchen. The order will be passed/routed to one of many chefs in the kitchen. They will eventually go through each order and prepare your food once your turn has come up. This is a simple analogy of how the actor system works. The waiters and the chefs are the actors in the system.
Actor works by communicating by passing messages between the actors. In the analogy above, the waiter actor passes the message (food order) to the kitchen and then to the chef. Each message passed between the actors is kept in an individual mailbox, and each message has to be processed sequentially.
How efficient is the communication between the actors is a crucial metric in the actor system. Depending on the setup, Ergo can sends over 5.9M messages per second between the actors in the same process. However, understandably, the throughput will be lower if the actors communicate over the network.
Each actor maintains its own state. In the analogy above, can for example count how many orders he/she has processed through out the day.
How does the actor model scale? In most cases, actors are very cheap (small memory footprint & very fast to be created). This is made possible with the tech breakthrough we have today. It’s common to see an actor system with millions of actors in a single machine. In Ergo system, each actor takes around ~1.24kb. 1 million actors only takes 1.24GB of your memory. In the analogy above, it’s so cheap to hire 1000s of waiters and chefs to prepare the food.
Example in code#
In simple Go code, the restaurant may operate like this:
// Maps of lanes in the fast food restaurant
orders := map[string]interface{}
// Waiter submits the order to the kitchen
orders["fadhil"] = {Item: "Satay Kambing", Count: 10}
// Chef checks for list of active orders and cook the food
for _, food := range maps.Values(orders) {
chef.cook(food)
}
However, the code will look very different in the actor model. The waiter and chef actors pass messages to each other.
// Spawn waiters actor in satay lane
satay1 := actorSystem.Spawn(ctx, "satay-1", NewWaiter())
satay2 := actorSystem.Spawn(ctx, "satay-2", NewWaiter())
// Spawn chefs actor in satay lane
chef1 := actorSystem.Spawn(ctx, "chef-1", NewChef())
chef2 := actorSystem.Spawn(ctx, "chef-2", NewChef())
// Customer telling the order to the waiter 1
actorSystem.Tell(ctx, satay1, Order{Item: "Satay Kambing", Count: 10})
// Waiter receiving food order, updating its local count state
// and submitting it to the chef
func (w *Waiter) ReceiveMsg(...) {
switch message.(type):
case *FoodOrder:
w.count = w.count+1
actorSystem.Tell(ctx, chef1, Order{Item: "Satay Kambing", Count: 10})
// Chef receiving food order and actually cooking the food.
// Once the food is ready, notify the waiter
func (c *Chef) ReceiveMsg(...) {
switch message.(type):
case *FoodOrder:
c.cook(*FoodOrder)
actorSystem.Tell(ctx, chef2, FoodIsReady{})
PS: The actual implementation is a bit more complex than what you see in the snippet above because it require you to generate protobuf code
Each actor type has its own way of handling the message received.
But why?#
There are many advantages to the Actor model.
- Fault tolerance. Each actor is an isolated process. When an actor dies or failed, it does not affect the other actors in the system.
- No race condition. This itself avoids a lot of complicated issues in programming. Each operation within the actor is processed sequentially.
- No locking & no contention. Since each actor is isolated, all operation within the actor does not need to wait for others.
- Slimmer infra. There is no need for a caching server, and in some cases, there is no need for job queues & external cron job setup.
Properties of an actor model#
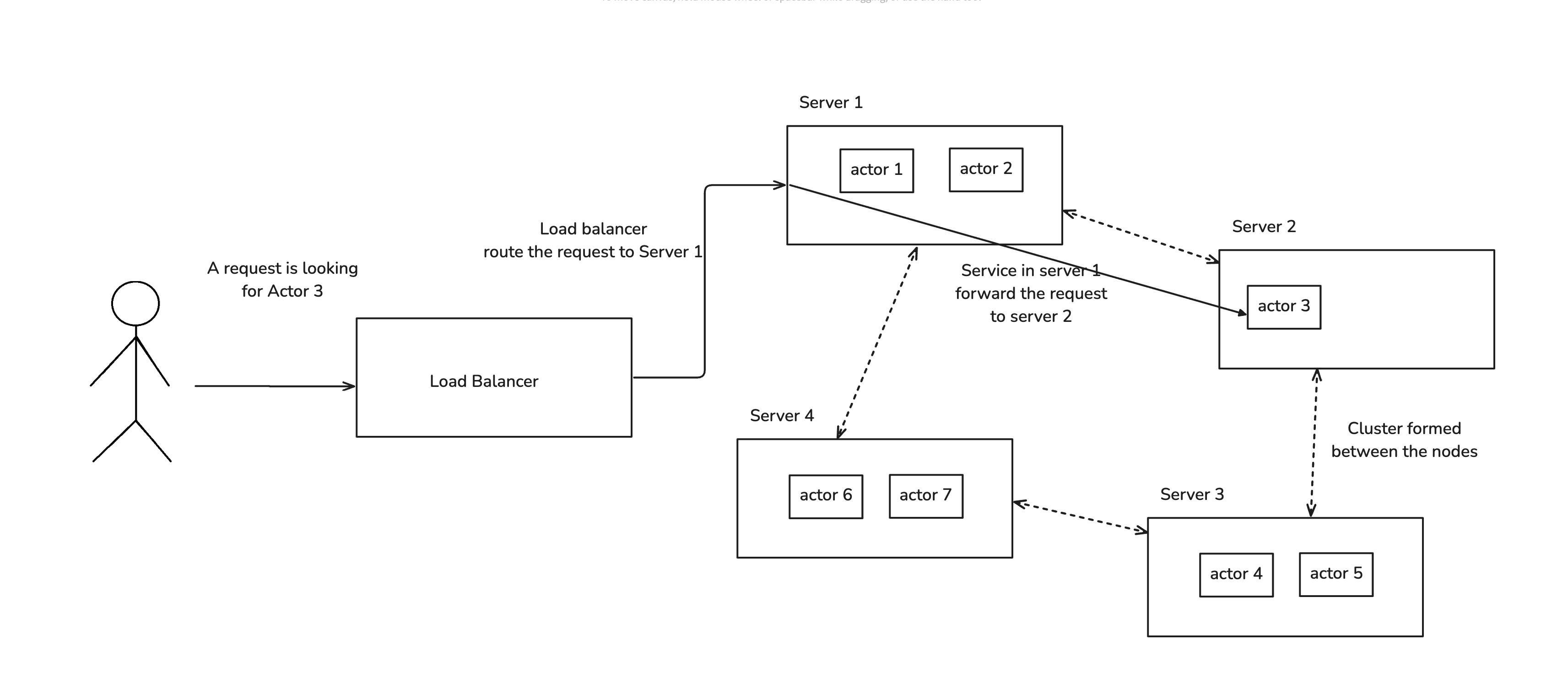
Diagram shows how a simple actor system works in a web server.
Writing a system with actor model requires a different kind of mental model compared to typical programming paradigm.
-
An actor is an object that exists once in the whole cluster. The actor system is aware and can communicate with all actors that exist across the entire cluster. The message sent to an actor is not lost even if the actor is stopped and respawned in a new node. For example, when you create a
user1actor, there could be only oneuser1actor in the whole cluster. Whenever you send the message touser1, it will reach the same actor no matter where it comes from. -
An actor maintains its own states. For example, you can set
user1actor with the following properties:{Name: "Fadhil", Age: 21}. When ever you want to access the actor where ever you are in the cluster, you will consistently see the same state. This means that your complex web service could serve as fast as your hello world application, with O(N) complexity. There is no need to access database (or caching DB like Redis) to get that data. More importantly, this could work like a write-through cache strategy and you won’t see stale data. -
An actor has a notion of workflow where it can schedule a task in the future. For example, if you want to collect a payment from each user every month, you can schedule the task for each user. This is similar to Cloudflare Workers Durable Object Alarms. This also means that you can buffer DB writes in the actor for a few seconds and then schedule a workflow every 10s (or any number you’re comfortable with) to flush/write the changes to the actual DB. With this, your DB don’t need to handle high write throughput and you can lower the spec of your database. This could work like a write-behind cache strategy and you won’t see stale data.
-
An actor can be mapped to a single row of your database since they are isolated. For example a single IoT device can be logically map the a single actor in your system. This is called digital twins in Akka.
Actor library comparison#
| Goakt | Ergo | Hollywood | Protoactor | |
|---|---|---|---|---|
| Inspired by | Akka | Erlang | Akka | Akka |
| Queue data structure | MPSC | MPSC | Ring buffer | MPSC & Ring buffer |
| First commit | Nov 2022 | Jan 2013 | Jan 2023 | Apr 2016 |
| What I like | Consice & feature complete. It has a testing toolkit and a CQRS meta-library called ego, it supports many service discoveries like Kubernetes & DNS, it support sharding/partitioning and passivation | It can communicate with Erlang. It is used in production in RingCentral, Kaspersky & Lilith Games | It is easier to get started since you don’t need to define structs in Protobuf | N/A |
| What it lacks | You’ll need to learn Protobuf since it’s used as its serialization data format | N/A | Lacks of some features like passivation | Documentation is not the easiest to navigate |
| Example project | goakt-realtimemap | N/A | hollywood-realtimemap | N/A |
Remember that all of these libraries are super fast, handling tens of thousands of requests per second. It’s just the preference of API now.
I personally like Goakt since it’s easiest to learn & the documentation has just enough information to explain each feature it has.
Ergo seems like an excellent library, especially if you have experience working with Erlang/Elixir. Moreover, the author claims it can process 5X more message throughput than Erlang. I personally did not have good experience working with Elixir, so this is a bit hard for me to pick up.
Goakt benchmark#
This is an example of benchmark of goakt-realtimemap running on AWS EC2 Spot machine. It essentially consume events of position of busses somewhere in Finland from a MQTT topic, keep them in memory as an actor state and serve its latest location at http://0.0.0.0:8080/vehicle?id=<vehicle_id>. Each bus is represented as an actor.
ubuntu@ip-172-31-19-182:~$ hey -c 1000 -z 1m 'http://172.31.36.71:8080/vehicle?id=0012.01214'
Summary:
Total: 68.7212 secs
Slowest: 0.0768 secs
Fastest: 0.0008 secs
Average: 0.0600 secs
Requests/sec: 127809.3217
Total data: 498890399 bytes
Size/request: 498 bytes
Response time histogram:
0.001 [1] |
0.008 [768027] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.016 [139074] |■■■■■■■
0.024 [32608] |■■
0.031 [50355] |■■■
0.039 [9134] |
0.046 [674] |
0.054 [116] |
0.062 [8] |
0.069 [2] |
0.077 [1] |
Latency distribution:
10% in 0.0017 secs
25% in 0.0035 secs
50% in 0.0045 secs
75% in 0.0076 secs
90% in 0.0152 secs
95% in 0.0246 secs
99% in 0.0312 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0000 secs, 0.0008 secs, 0.0768 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0000 secs
req write: 0.0002 secs, 0.0000 secs, 0.0290 secs
resp wait: 0.0434 secs, 0.0008 secs, 0.0358 secs
resp read: 0.0096 secs, 0.0000 secs, 0.0437 secs
Status code distribution:
[200] 1000000 responses
The load test completed with 100% success, with no error observed. You don’t need to worry about lock contention & race condition. P99 is at 31ms, thats mad!
Update Dec 2024: I recently updated the library to v2.10.0 and I could observe 2ms P99 on my laptop. There are a lot of improvements committed by the author since I conducted this load test.
I tested with several other setups and the result is as follows:
| CPU Cores | 4 | 8 | 10* | 32** | 64** |
|---|---|---|---|---|---|
| Requests per second | ~40,000 | ~80,000 | ~100,000 | ~170,000 | 200,0000 |
* This is ran on my M1 Macbook Pro
** Machines with 32 & 64 cores are not set up with Elastic Network Adapter so perhaps the machines did not use the NIC to its fullest.
*** All EC2 machines are using ARM cores.
When I ran the load test, I set up the server & client on separate machines with similar spec to make sure that they are not competing for resources. The load test was conducted using wrk.
Downsides#
-
Writing a software with actor model becomes more complex than the typical paradigm we used to. That means, the cost of writing & maintaining the code is also higher.
-
You are now taking care of stateful services. Since actors live in the servers now, you have to make sure that they don’t get killed unexpectedly and they have enough time to migrate to new servers when you wish to kill them. This also means that blue-green deployment strategy doesn’t work best with actor model.
-
Multi region deployment gets more complex. Due to high latency observed when communicating between the regions, there are a lot of ugly things could happen when actors try to communicated between the regions. Because of this, Akka build actor with CRDT data structure.
If you think that the benefits outweigh the downsides of actor model, especially if you care the most about performance, then only you should look forward into this.
Conclusion#
In 2022, I wrote an article on How I would build JKJAV site to cater to high write throughput from all over Malaysia. My benchmark with Redis says it could reach up to 3,000 req/s on my laptop. However, with the example above, I can easily reach 100,000 req/s, which is 30x higher throughput than Redis, achieving this with one less external dependency. The Redis solution sounds like child play compared to the Actor model!
Actor model is pretty new in Go. I hope this article inspires you to explore this paradigm and support these fantastic libraries!